“Work it harder, make it better. Do it faster, makes us stronger. More than ever, hour after hour. Work is never over.” – Daft Punk from “Harder, Better, Faster, Stronger.”
Daft Punk must’ve had CyberGRX in mind when writing that song. Let me explain.
CyberGRX was founded in 2015 to facilitate sharing Third-Party Cyber Risk (TPCRM) data between companies. Part of that journey has been launching our predictive assessment capability, where we can ingest a vendor onto our platform and predict how they will answer a risk assessment with a high degree of confidence.
Our goal is to provide our customers with timely data on third-party vendors. A crucial part of our model is processing every company in our platform through the predictive analytics system. This data needs to be provided in a timely fashion, and after several iterations, AWS Step Functions with AWS Lambda were selected as the technologies to accomplish the processing.
Challenges to Overcome
As we approached this project, we had a few obstacles to overcome. Namely:
- How do we convert our existing Docker, Kubernetes, and Argo Workflows based process into AWS Step and Lambda with minimal changes to the code?
- How do we solve the singular case, the subset case, and the full Exchange case for processing?
- Where are the scaling bottlenecks that need to be overcome? There are currently over 150,000 companies in our Exchange, growing constantly.
Challenge 1: Building the Containers
Our team had an existing build process based on AWS Codebuild for generating Docker artifacts that are then orchestrated on EKS. The first iteration of this process ran on this platform, but we quickly ran up against the limits of what Kubernetes and Argo Workflows could handle effectively. We were limited by the number of items that could be processed, had to deal with many errors, and the process required a lot of babysitting to finish. To overcome this, we wanted to adapt the current process with minimal changes to our current build process. It turns out that adjusting the code was relatively straightforward. Our first implementation was geared towards Argo Workflows and using input/output files on disk:

Since Lambda provides an input, we decided it would be best to just pass the parameters directly to Lambda as an event and process it that way. Since the input files exceed the 256Kb limit in Step function parameters, we store them in S3 and pass references to them so each step can pull the data from S3 and process it. This provides a means for us to review the inputs and persistence if the process fails. Pulling the data this way required minimal code changes as we’re still reading files and only changing the location. Note that this was somewhat fortuitous as there are limits to the size of files you can pass between steps in step functions, and some of the inputs are quite large. As it turns out, setting this up was pretty straightforward:
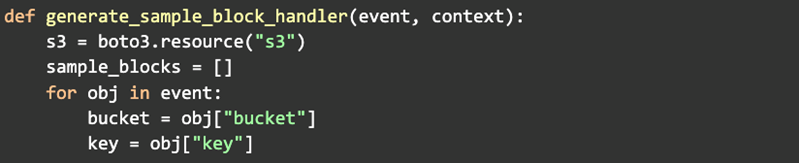
Now that we could handle a Lambda using an almost identical code path, we needed to update the build process to generate a container that Lambda understands. Again, this was pretty easy to do. We are using Docker to generate our artifacts and just needed to add another build step:
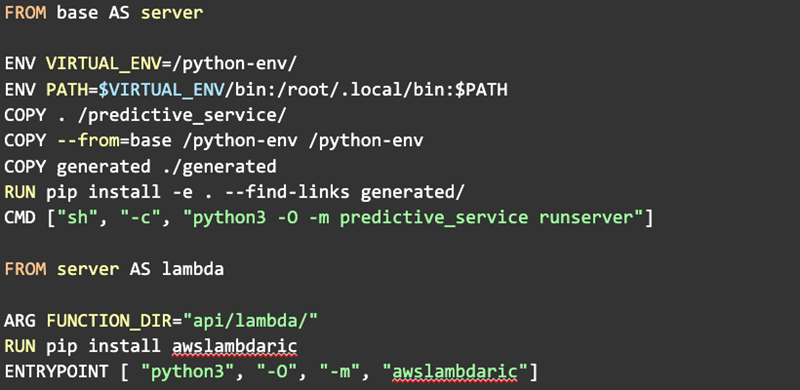
When using an image with Lambda it lets you override the COMMAND parameter. We just passed in “predictive-service.api.lambda.generate_sample_block_handler” and it worked. Rinse and repeat for the remaining services we need to use in this process.
Challenge 2: Creating a Cohesive Input
Creating a cohesive input was more of a conceptual problem. We needed this system to be able to compute predictive data when a company was added or changed in the Exchange and when we updated the model. The former was a singular case or a small batch, and the latter was every company currently on our platform. These events are distinct, and we settled on using SQS to drive the input to the pipeline. This lets us add each company to the system as a discrete event and acts as a buffer for processing as many as it can handle. It also provides a cohesive input to the predictive engine; rather than having separate invocation paths, we now have a single place to drop inputs to start the process. Initially, we attempted to use Kinesis but realized that the semantics of Kinesis with shards, streams, and order guarantees were more overhead that we didn’t really need to deal with. Which led to the final challenge, how do we get this thing to scale?
Challenge 3: Scalability
Tuning all the moving parts for scalability was the final and most interesting hurdle. At this point, everything is wired up and running. Submitting a job fires the pipeline and runs it to completion. The following diagram shows how data traverses the pipeline:
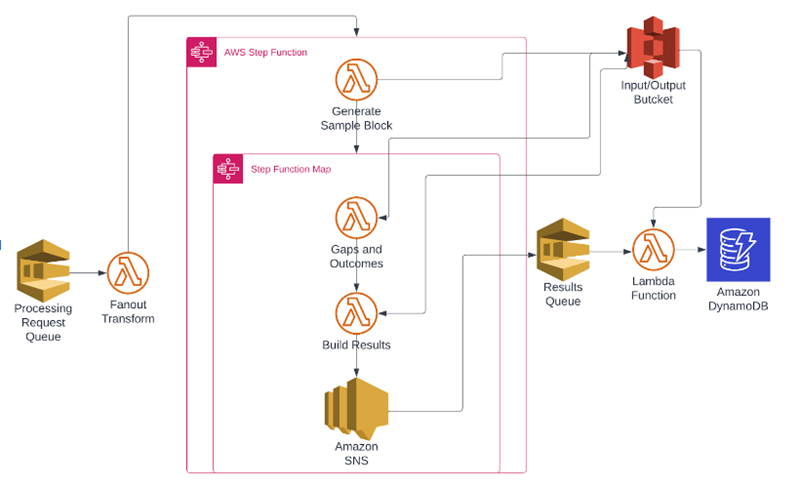
Each step generates an S3 object and passes a reference to that object into the next step. Finally, the objects are loaded, processed, and the results pushed to S3 for further processing. This process runs pretty well for a single unit of work; it’s when you want to run thousands of them at a time that it starts to fall apart.
When you open an AWS account, you are given a maximum concurrency of 1,000 running Lambda functions. Thinking about the whole use case of 150,000 companies, even if we could run 1,000 at a time, it would take around 24 hours to process the entire pipeline. That doesn’t seem so bad except that the Exchange is growing every day, and as we add companies, that would get longer and longer. We want this to be fast enough to run in a relatively short time to give us room to grow.
The first parameter we tuned was asking for more concurrency. We asked for and received a maximum concurrency of 20,000. To test this, we ran 21,000 jobs through the system and immediately discovered several problems. First, you’re limited to a burst rate of 3,000 requests across your account, adding 500 per minute after that. This had some side effects on the rest of our system, with other Lambda functions struggling to start while we ran this. Definitely not a good thing; other critical business Lambda functions need to run. The other problem we discovered was that jobs were not being re-queued when they failed once they passed the Fanout Transform function. So when they failed, the job was dropped entirely and lost.
To solve the problem of side effects, we went through the other functions in the system and gave them reserved concurrency and at least one provisioned concurrency. That ensured that they could still run while this system was processing a large job. So, one problem is solved: how do we ensure messages are not lost and keep the pipe full while it ramps up the concurrency?
It turns out that it takes attacking the concurrency issues from multiple angles. The first one we realized is that the internal state of the step function in the figure above makes it almost impossible to re-queue jobs once they make it that far. Although initially, we had the first step run a parallel map of 10 (the maximum) separate pipes, we reduced that to three to slow down the parallelism for each step execution. This lets the system have more work in flight while at the same time using as much parallelism as we could. After adjusting the parallelism, we updated the Step pipeline itself to catch all Lambda-related errors and retry steps if they failed with very generous amounts of retry in the pipeline:

At this point, we could ensure that once a step execution was started, it should finish. We now needed to figure out how to create step executions in such a way to keep about 19,000 Lambdas running at a time (something we still haven’t actually achieved, but we’re getting closer). The number 19,000 was chosen rather than 20,000, so the original account limit of 1,000 was reserved for other processes.
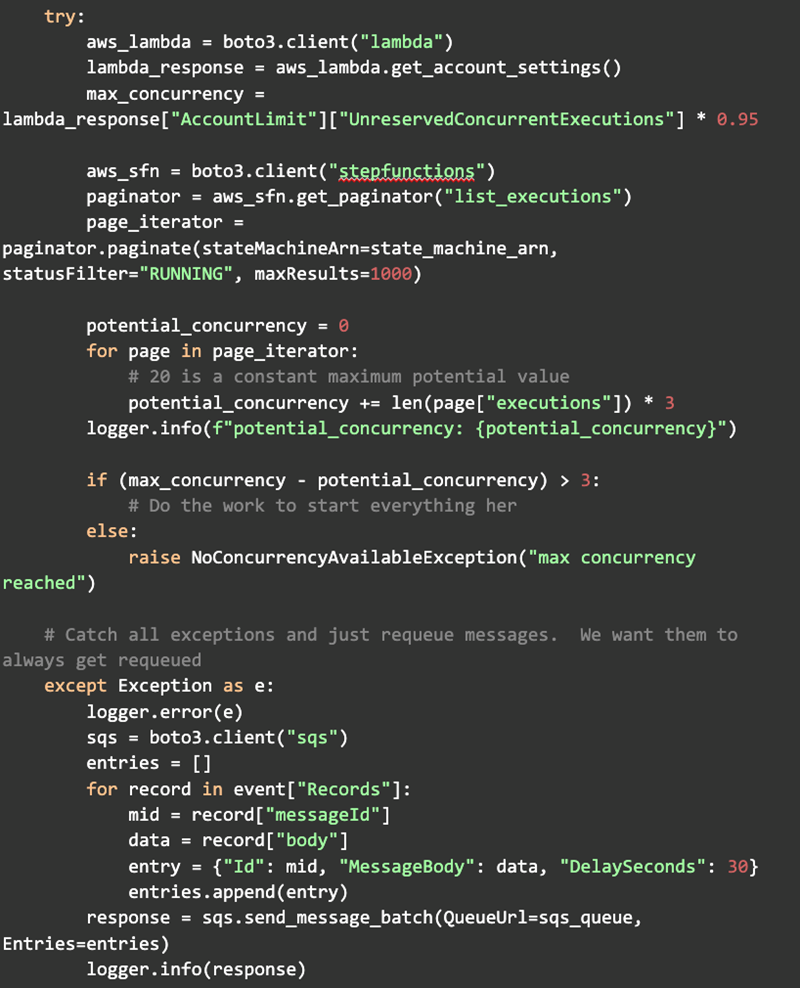
Now we’re close to having it work at the scale we need. There’s just one more thing we need to put in place. We need logic in the Fanout function that understands what is going on and the limits to ensure that the Step functions stay full while simultaneously ensuring that messages aren’t lost. It turns out that was a relatively simple bit of code. For example, we could query the Step API for how many Step executions were currently in flight, multiply that by 3 for the maximum potential concurrency, then subtract that from the actual maximum of 19,000. If that number is greater than 3, we have room to start another; otherwise, re-queue the message and delay for 30 seconds before retrying:
All of this looks good so far; how does it look in practice? Are we getting the concurrency we want? It turns out that we’re getting pretty close out of the gate. Initially, we hit a bottleneck that you can see around the 13:30 mark in the next graph. Then, we tuned the producer Lambda to give it more reserved concurrent executions, and around the 14:10 mark, the system took off.
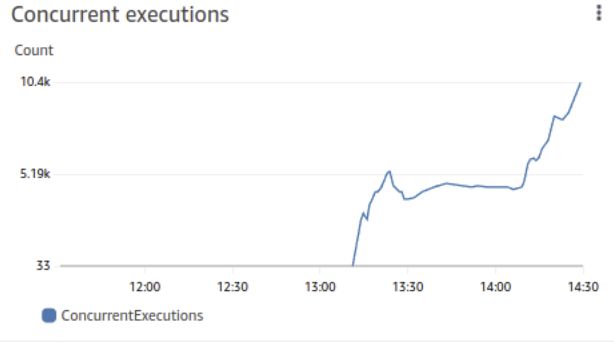
Conclusion
Once all of this was tied together, it worked very well. There’s still some tuning to keep the pipe full, such as better leveraging provisioned concurrency and using target tracking policies to preemptively start scaling up the functions, but we’re happy with the results. The first full run took about 95 minutes which is far faster than the 5 days of our old system. It could only use about 80% of the total capacity, so we expect better numbers in the future with a little more parameter tuning. Best of all, it solves every use-case we have and runs without babysitting.
Updating the model is a simple process of just filling SQS with all the data we need to process and letting it work. The door is also now open for our team to build a parallel pipe to speed up the development of new models. Overall, we’re pleased with this first iteration of our new machine learning pipeline.
Charles Burton is the Linux/Unix wizard in residence at CyberGRX. In his role, he designs and builds most of the infrastructure for the CyberGRX analytics team. In addition, he is also a strong advocate for Infrastructure as Code, building systems that look to the horizon of what needs to be accomplished now and in the future.
If you’d like to see the CyberGRX Exchange in action and how it can improve your TPCRM, we invite you to book a demo now.
Related Articles

Managing Third-Party AI Risk
Artificial Intelligence presents third-party risk management (TPRM) professionals with a serious challenge and a profound..
Learn More
Ransomware Attacks in Healthcare: How to...
Healthcare organizations are common targets for cyber and ransomware attacks. Because organizations in this industry..
Learn More
5 Red Flags by Third-Party Risk...
Third-party risk management (TPRM) teams have a challenging job: they must evaluate a large volume..
Learn More
Deploying an AI-powered Third-Party Risk Management...
Artificial Intelligence (AI) impacts third-party risk management (TPRM) practices, whether or not your TPRM team..
Learn More
ProcessUnity is a Leader in the...
The results are in: ProcessUnity is a Leader in the 2024 Forrester Wave™ for Third-Party..
Learn More
Quantify Financial Risk to Prioritize Third-Party...
When you quantify financial risk across your third-party ecosystem and prioritize the most critical remediation..
Learn More
FDA Cybersecurity Regulations Add Medical Device...
As more medical devices are produced to function wirelessly and with network capabilities, the risk..
Learn More
NIST CSF 2.0 Draft Emphasizes Cybersecurity...
The National Institute of Standards and Technology’s Cybersecurity Framework (NIST CSF) has helped organizations of..
Learn More
Mature Your Cyber Program with a...
Risk-based cybersecurity risk management is the process of identifying, tracking and mitigating the risks to..
Learn More
The Relationship Between Privacy vs Security...
30 years ago, privacy, security, and risk management were rarely used in the same sentence...
Learn More

3 Practices to Ensure Supply Chain...
Supply chain resilience, or the ability to withstand and manage disruptions to your supply chain..
Learn More
Electric Utilities and the Domino Effect...
A few years ago, cyberattacks with physical effects, like Stuxnet, were relatively unheard of. In..
Learn More

Inside the Breach: Unraveling Iconic Data...
If you were to Google “cyber attacks on critical infrastructure,” you would get over 27..
Learn More
How the SEC Cybersecurity Rule Impacts...
As of July of 2023, public companies are subject to new cybersecurity disclosure requirements from..
Learn More
From Infiltration to Execution: Understanding the...
There is no silver bullet, although, believe it or not, there is a silver lining..
Learn More
Unveiling the Power of a Risk...
If you feel overwhelmed by bespoke security questionnaires, you're in good company. Many understand the..
Learn More
Controls-Based Versus Risk-Based Cybersecurity Programs
In the face of an escalating regulatory burden and increasingly common data breaches, many teams..
Learn More3 Key Takeaways from ICON plc’s...
ICON Plc recently received the award, “Best in Class Third Party Risk Management—Large Enterprise,” from..
Learn More
Manage Cybersecurity Risk with the SCF...
The Secure Controls Framework (SCF) Risk Management Model can be a powerful tool for teams..
Learn MoreCyberGRX Ranked on the 2023 Inc....
It’s been said that good things happen in three’s, and that’s certainly true with the..
Learn More
Use Software to Follow OCC 2023-17...
The Federal Reserve, Federal Deposit Insurance Corporation (FDIC), and the Office of the Comptroller of..
Learn More
21 Cybersecurity Training Resources
According to Statistica, the global cost of cybercrime is expected to reach a staggering $24..
Learn More
The SEC Cybersecurity Rule and the...
When the government perceives those entrusted to its care are in danger, it takes action—..
Learn More
What Role Does AI Play in...
Would you use AI to support your third-party risk decisions? We’ve recently witnessed AI morphing..
Learn More
Cybersecurity Through the Years and How...
“Security is a process, not a product.” - Bruce Schneier From the mainframes of..
Learn More
3 Takeaways from Retail Cybersecurity Breaches
Retail businesses process large quantities of transactions and customer data, making them common targets for..
Learn More
CyberGRX and ProcessUnity Combine to Form...
July 12, 2023 – CyberGRX and ProcessUnity announced today that the Third-Party Risk Management (TPRM)..
Learn More
ADP Reaches CyberGRX Exchange Risk Assessment...
ADP has reached a significant assessment-sharing milestone, sharing its validated cyber risk assessment over 1,000..
Learn More
Optimize Vendor Onboarding by Aligning with...
During the vendor onboarding process, both cybersecurity and procurement manage the amount of risk brought..
Learn More
How ISO 27002 Prepares You for...
ISO 27002 is a powerful tool to demonstrate your information security commitments to customers, investors..
Learn More
CyberGRX Enables Microsoft to Expedite Risk...
We are pleased to recognize Microsoft for expediting the sharing of risk assessments and merging..
Learn More
MOVEit Breach Fallout | LastPass Regrets...
In this episode of GRXcerpts: The MOVEit Breach Fallout Continues LastPass Reflections and Regrets Updates..
Learn More
Align Your Organization with the NYDFS...
The NYDFS Cybersecurity Regulation (23 NYCRR 500) is a set of rules designed to enforce..
Learn More
Malicious Chrome Web Extensions | Cyber...
In this episode of GRXcerpts: Malicious extensions found on the Chrome Web Store Cyber insurers..
Learn More

Mitigate Shadow IT Risk Internally and...
Shadow IT, or technology that’s used without being documented or vetted by cybersecurity personnel, poses..
Learn More
Navigating the Supply Chain Risk Landscape...
The supply chain risk landscape continuously changes, posing constant cyber risks and threats to manufacturers...
Learn More
Manufacturing Under Attack: Unmasking the Risks...
According to the World Economic Forum, manufacturing is one of the most targeted sectors by..
Learn More
Inside the Breach: Why & How...
One single vulnerability is all a hacker needs. In 2022, manufacturing firms suffered more than..
Learn More
Standing Tall: The Role of Security...
A resilient security posture shouldn’t be taken for granted, especially with a constantly changing threat..
Learn More
Align Your Cybersecurity Program with NIST...
Aligning your cybersecurity program with NIST 800-53 involves mapping your controls and policies to the..
Learn More
3 Ways to Prepare Your Cybersecurity...
SOC 2 compliance can be a powerful tool for all aspects of your business—it can..
Learn More
Google's New Top-Level Domains | Microsoft...
In this episode of GRXcerpts: Google’s top-level domains open doors to new attack vectors Warnings..
Learn More
Navigating the Cybersecurity Landscape of Energy...
Cyber threats pose a serious risk to energy systems globally, potentially bringing critical energy infrastructure..
Learn More
Responsibly Defend Cybersecurity's Budget
Though the cybersecurity function is as crucial as ever, recession, inflation and widespread layoffs have..
Learn More
The Risk Reporting Dilemma: Balancing Transparency...
No one likes to be the bearer of bad news, but even though it’s a..
Learn More
3 Features to Look for in...
Choosing the right third-party risk management tool for your organization requires identifying the functionality that..
Learn More
The State of Cyber Risk Management...
In the financial services industry, cyber risks and threats have become an inherent part of..
Learn More
Rising Threats & Risk Management Challenges...
In 2022, the insurance and finance industries were the second-most targeted sector in terms of..
Learn More
Inside the Breach: Understanding Patterns &...
Insurance and financial companies, with thousands of corporate and private clients, are lucrative targets for..
Learn More
The Top Risk Management Challenges Facing...
Retail and hospitality organizations now find themselves in the cybersecurity line of fire. According to..
Learn More
QR Code Scams | Q1 Cyber...
In this episode of GRXcerpts: Alarming new QR code scams Cyber attack stats for Q1..
Learn More
Inside the Breach: Unmasking the Types...
Without question, technology has revolutionized how we do business today. But with great power comes..
Learn More


The State of Cyber Risk Management...
Risk represents the potential for damage when a threat source exploits a vulnerability. In the..
Learn More
The State of Cyber Risk Management...
Risk is an ever-present threat, capable of inflicting substantial harm when vulnerabilities are exploited by..
Learn More
Managing Cyber Risk in the Digital...
The increasing demand for technology solutions in an era of digital transformation presents both opportunities..
Learn More
How to Choose Trust Service Criteria...
Selecting Trust Service Criteria (TSC) is a crucial step in achieving SOC 2 compliance: the..
Learn More
CyberGRX Ranks Among Highest-Scoring Businesses on...
Inc. Magazine has recognized CyberGRX as a Top Workplace 2023, honoring 591 exceptional companies from..
Learn More
Inside the Breach: Analyzing Iconic Data...
The US hospitality market was worth $4.1 trillion in 2022 and will see strong growth..
Learn More
Why Ignoring TPRM is Increasing Your...
It seems that not a week goes by without a data breach or cyber attack..
Learn More
3CX Hackers Target Critical Infrastructure |...
In this episode of GRXcerpts: 3CX hackers target critical infrastructure A warning to critical infrastructure..
Learn More
Using Third-Party Risk Management Software for...
Third-party risk management (TPRM) is an umbrella term for the process of tracking and mitigating..
Learn More
CyberGRX Announces Winners of the Inaugural...
April 26, 2023 – CyberGRX, provider of the world’s first and largest global risk exchange,..
Learn MoreCyberGRX Named Winner In 11th Annual...
April 24, 2023: Cyber Defense Magazine announced today that CyberGRX won a 2023 Global InfoSec..
Learn More
Nth Party Relationships and Supply Chain...
No person–or company–is an island. In today’s interconnected, digital world, most, if not all, organizations..
Learn More
A Control Metaframework Can Unify NIST,...
Cybersecurity teams often need to achieve compliance with multiple regulations, standards and frameworks. The sheer..
Learn More
The Impact of the SEC Cyber...
In this special edition of GRXcerpts, we’re diving into the pending SEC cybersecurity regulation and..
Learn More
Pushing Boundaries: Accelerating Risk Decisions With...
The alarming volume of cyber attacks that businesses and organizations face today emphasizes the need..
Learn More
Prepare for DORA with a Cyber...
Cyber risk management is now a requirement for financial organizations in the EU and the..
Learn More
3 Takeaways about Anti-Bribery and Corruption...
Anti-bribery and corruption programs grant businesses visibility into their internal practices and third-party networks to..
Learn More
How Well Do You Know Your...
How well do you know your third parties? Are your records accurate and up-to-date? Modern..
Learn More
CyberGRX Named Security Visionary in EMA...
April 4, 2023 - Enterprise Management Associates (EMA), a leading IT and data management research..
Learn More
QR Code and PDF Scams, ChatGPT...
In this episode of GRXcerpts, we’ll cover technologies you thought were relatively safe but might..
Learn More
3 Due Diligence Obligations for the...
The German Supply Chain Act (LkSG), effective as of January 1, 2023, imposes new due..
Learn More
Your TPRM Program Must Account for...
Global conditions, from civil unrest and political turmoil to questionable government practices, can affect operations..
Learn More
Managing Cyber Risk Amidst a Growing...
As the world becomes more interconnected, businesses increasingly rely on third-party vendors to provide essential..
Learn More
The Impact of SVB on Cybersecurity,...
In this episode of GRXcerpts: The Impact of SVB on Cybersecurity New TSA measures for..
Learn More
Show Executives that Cybersecurity Drives Operational...
One strong approach to justifying your cybersecurity budget to executive leadership is to show how..
Learn More
Add Data and Risk Intelligence to...
CyberGRX is proud to announce the launch of our ServiceNow VRM integration, designed to provide..
Learn More
CyberGRX Integrates with ServiceNow to Streamline...
March 15, 2023 – CyberGRX, provider of the world’s first and largest global risk exchange,..
Learn More
CyberGRX Recognized for Innovation and Collaboration...
CyberGRX has been named the recipient of eight awards from the 2023 Cybersecurity Excellence Awards..
Learn More
Third-Party Risk Management: the Key to...
Scroll through social media, and you’ll come across many motivational tips and challenges about..
Learn More
Maturing Your Program with a Cyber...
Many organizations spread their cybersecurity budget between a variety of technologies, services and vendors: they..
Learn More
Discover Hidden Portfolio Vulnerabilities and Evolve...
Portfolio Risk Findings highlights the risk hidden inside your portfolio when analyzed through a specific..
Learn More
New Rules Strengthen SEC Cybersecurity Oversight...
The United States Securities and Exchange Commission (SEC) has recently announced a set of new..
Learn More
Data Risk Management Challenges and Best...
Protecting your data against unauthorized access and cyberattacks is hard. And, cybersecurity teams often question..
Learn More
CISO Stress Report, Dole Supply Chain...
In this episode of GRXcerpts: Are CISOs too Stressed? The Dole Supply Chain Disruption Ongoing..
Learn More
New FSRA Guidance Emphasizes Operational Risk...
The Financial Services Regulatory Authority of Ontario (FSRA) recently released guidance for credit unions and..
Learn More
4 Tips for Justifying a Bigger...
Economic uncertainty presents cybersecurity teams with new challenges: while each round of big tech layoffs..
Learn More
Diversity in Cybersecurity: What It Means...
In 2020, a reckoning emerged in the wake of several high-profile racial incidents. As the..
Learn More
Overcoming TPRM Shortages with Risk Prioritization
It is not uncommon for organizations to have hundreds of third-party relationships. And, a comprehensive..
Learn More
3 Tips for Aligning Internal and...
While cybersecurity traditionally owns control assessments, they need help from procurement to get a true..
Learn More
CyberGRX Launches Portfolio Risk Findings to...
February 22, 2023 – CyberGRX, provider of the world’s first and largest global risk exchange,..
Learn More
Clop Ransomware, New Credential-Stealing Malware, Prioritizing...
In this episode of GRXcerpts, get updates on: Clop Ransomware and GoAnywhere MFT Vulnerabilities New..
Learn More
Are Third-Party Social Engineering Gaps Leaving...
Phishing is one of the top ploys used by cybercriminals to gain access to your..
Learn More
How Healthcare Security Leaders Can Mitigate...
Healthcare organizations have faced serious challenges in recent years, and while the pandemic has been..
Learn More
How to Be Proactive About Incident...
Let’s face it, the threat of cyber attacks is a constant concern. No matter what..
Learn More
Cybersecurity News: Hive Ransomware Takedown, APT29...
In this episode of GRXcerpts: Hive Ransomware Takedown Russian-Linked APT29 Malware Breach Notifications Closing the..
Learn More
New Year, More Complex Threat Landscape
Wouldn’t it be nice to start a new year and think to yourself, “THIS will..
Learn More
Do Security Ratings Give a False...
Security ratings are a hot, yet controversial topic. They provide a quantifiable assessment of risk,..
Learn More
Cybersecurity News: ChatGPT Concerns for Cybersecurity,...
As attacks on critical infrastructure have increased around the globe, the US Department of Energy..
Learn More
Drive Action Through Third-Party Risk Insights
There are many third-party risk management options on the market, and while some can give..
Learn More
CyberGRX Leverages MITRE Techniques to Uncover...
Denver, CO -- January 18, 2023 – CyberGRX, provider of the world’s first and largest..
Learn More
Properly Scoping Vendor Due Diligence Drives...
Properly Scoping Vendor Due Diligence Saves Both Time and Money One of the costliest mistakes..
Learn More
Security Assessments 2.0: The Next Generation...
The more things change, the more they stay the same. It's a well-worn adage that..
Learn More
Next-Level Strategies for an Efficient Third-Party...
How to Optimize Third-Party Due Diligence for Cybersecurity According to IBM’s Cost of a Data Breach..
Learn More
Don’t Treat Third-Party Risk Management as...
Beyond Basic Compliance: Achieving True Resilience Requires Third-Party Risk and Cybersecurity Alignment Between SOC audits,..
Learn More
Reflections on Cybersecurity Events from 2022...
Hear from CyberGRX staff as they reflect back on the notable cybersecurity events from the..
Learn More
How the Role and Priorities of...
The role of a Chief Information Security Officer (CISO) is changing. While 76% of CISOs..
Learn More
How to Conduct Third-Party Due Diligence
Identifying and engaging with the right partners is essential to the success of most businesses...
Learn More
Cybersecurity News: Cuban Ransomware, Healthcare Vendor...
Trending headlines in cybersecurity: Microsoft Warning for European Organizations Cuban Ransomware Attacks World Cup Phishing..
Learn More
Inherent Risk & Residual Risk...What's the...
You’ve worked hard to develop, implement, and continually improve your cybersecurity program, recognizing your organization..
Learn More
Ho Ho HACKED! Ransomware Awareness for...
‘Tis the season for ransomware awareness because, for hackers, ‘it’s the most wonderful time of..
Learn More
Cybersecurity News: The Impact of our...
Trending headlines in cybersecurity: The 8th Google Zero Day Threat of 2022 An Aggressive Qakbot..
Learn More
How Automated ESG Due Diligence Makes...
Over the past few years, Environmental, Social, and Governance (ESG) regulations have become increasingly rigorous..
Learn More
Keep the Cyber Grinch Out: Holiday...
The holidays are just around the corner– and so are the cyber grinches, waiting for..
Learn More
Cybersecurity News: Mandates for Financial Services,...
Trending headlines in cybersecurity from the week: State of Industrial Cybersecurity New Regulations for Financial..
Learn More
Cybersecurity News: Education Grants, Twitter Phishing...
Trending headlines in cybersecurity from the week: Cybersecurity Clinics Program Act Phishing Caution to Twitter..
Learn More
Cybersecurity News: Twitter Phishing Cautions, Passwordless...
Trending headlines in cybersecurity from the week: Cybersecurity Clinics Program Act Phishing Caution to Twitter..
Learn More
Security Assessments: Waste of Time or...
It’s the million-dollar question: is the juice from security assessments worth the squeeze? We all..
Learn More
What Classic Rock Teaches Us About...
It’s well documented that music generates an emotional response for most people. And there’s actual..
Learn More
Creating a Culture of Security: Best...
We all know zero risk is impossible, but there’s still plenty of room for improvement,..
Learn More
CyberGRX Ranked No. 220 Fastest-Growing Company...
Denver, Co. -- November 16, 2022 -- CyberGRX, provider of the world’s first and largest..
Learn More
New Artificial Intelligence Regulations Will Require...
The frontier is closing on artificial intelligence: Where AI once represented the “Wild West” of..
Learn More
Cybersecurity News: Cyber Insurance, Media Supply...
Trending headlines in cybersecurity from the week: Cyber insurance rates stabilizing and decelerating in 2023..
Learn More
Cybersecurity News: Ransomware Summit, SEC Regulations...
Trending headlines in cybersecurity from the week: The second annual global Ransomware Summit Changes to..
Learn More
Diaxin Ransomware, Windows Zero-Day Threat, 6G...
In this episode of GRXcerpts, we keep you updated on interesting and trending headlines in..
Learn More
CyberGRX Spotlighted in TAG Cyber Analysis...
Denver – October 18, 2022 – CyberGRX, provider of the world’s first and largest global..
Learn More
Budgeting for Your TPRM Program
With two consecutive drops in real GDP in 2022, 1.6% and 0.9% for the first..
Learn More
Deepfakes, Zoom High-Priority Patch, Authentication Updates
Welcome to GRXcerpts, highlighting interesting and trending headlines in cybersecurity. Stay informed in less than..
Learn More
Security Shift: From Cyber Threat Intelligence...
The traditional approach to cybersecurity is broken. Data tells the tale: Despite the development and..
Learn More
Checklist: TPRM Budget Preparation
Download Now Considerations to assist in preparing for your annual third-party risk management (TPRM) budget..
Learn More

What Cyber Risk Isn’t Third-Party Risk?
We thought 2021 was a record-breaking year for cyberattacks. And it was. Compared to 2020,..
Learn MoreCyberGRX Named Winner in ‘Threat Intelligence...
DENVER - Oct. 6, 2022 – CyberGRX, provider of the world’s first and largest global..
Learn More
Trust: A Hidden (Yet Valuable) Benefit...
Trust is one of the most powerful currencies in business, but it’s hard to earn..
Learn More
ProcessUnity Customer Summit: Experts Advocate for...
At the 2022 ProcessUnity Customer Summit, experts from a variety of industries and organizations convened..
Learn More
10 Ways to Make your TPCRM...
It seems that not a week goes by without a data breach or some other..
Learn More
CyberGRX Recognized with Frost & Sullivan’s...
Denver, CO -- September 27, 2022 – CyberGRX, provider of the world’s first and largest..
Learn More
The 4 Essential Pillars of a...
Toyota’s factories, which pump out over 10 million vehicles every year, screeched to a halt..
Learn More
If Total Risk Elimination is Impossible,...
Zero isn't possible. No matter how much money you spend on cybersecurity, how many people..
Learn More
Infographic: The Dark Side of Digital...
According to Tech Pro Research, 70% of organizations either have or are working on a..
Learn More
Evolving TPCRM with a Data-Driven Approach
Likely no one in our industry will dispute the traditional approach to third-party cyber risk..
Learn More
5 Tips for CISOs About the...
To quote Bob Dylan, "the times, they are a-changin'." A decade ago, all eyes were..
Learn More
Evaluating Security Risk When Onboarding New...
In today’s tightly interwoven supply chains and highly competitive markets, organizations must continuously evaluate and..
Learn More
How Risk Managers Are Reducing Enterprise...
“Take calculated risks. That is quite different from being rash.” These words of wisdom from..
Learn More
Third-Party Risk Assessments: Are They Effective...
It’s the million dollar question every cybersecurity practitioner has in the back of their minds…do..
Learn More
The Human Impact of a Cyber...
News flash! Headlines about cyber attacks don’t tell the whole story. The world is in..
Learn More
Which Cybersecurity Certification Does Your Business...
More customer wins. Better organizational security. Efficient compliance management. These are just a few of..
Learn More
Why You Need Continuous Monitoring of...
Working with a third-party vendor is a lot like inviting someone into your home during..
Learn More

3 Business Benefits of a Cybersecurity...
Cyber risk is a top concern for businesses today thanks to the ubiquity of the..
Learn More
How Does Third-Party Risk Fit Into...
In today’s digital economy, it’s rare to find an enterprise or corporation that manages every..
Learn More
RSA Conference 2022: Transformation, TPCRM, and...
What. An. Event! Imagine…26,000 cybersecurity professionals learning and networking IRL for the first time since..
Learn More
GRC 20/20 Quantifies Return on Investment...
Independent research examines the measurable benefits of ProcessUnity VRM Imagine what business results you could..
Learn More
Zero Trust as a Third-Party Risk...
According to a Microsoft survey, more than 40% of workers are considering quitting their jobs..
Learn More
CyberGRX Use Case Guide
CyberGRX is the Cyber Risk Intelligence industry leader. Within the CyberGRX Exchange, we have an..
Learn More
CyberGRX Named Winner In 10th Annual...
CyberGRX recognized as Hot Company in the Third-Party Cyber Risk Management (TPCRM) category for its..
Learn More
CyberGRX and Google Cloud Collaborate to...
Google Cloud to satisfy risk and procurement needs across wide customer base and deliver a..
Learn More
How a Data-Driven Approach to TPCRM...
When it comes to TPRCM (Third-Party Cyber Risk Management), the scope of potential threats outside..
Learn More
How an Exchange Supports an Effective...
According to a recent report by Deloitte, organizations spend 10.9% of their IT budgets on..
Learn More
Building a TPCRM Program: Where to...
Today's organizations have become increasingly reliant on third-party vendors to help them grow and sustain..
Learn More
How Common Are Third-Party Security Breaches?
In terms of operational agility and cybersecurity, third-party service providers can be a double-edged..
Learn More
Cyberattacks and Breaches can Severely Damage...
Cybercriminals want your data and they don’t care about the fallout for your organization. The..
Learn More
CyberGRX recognized by EMA as a...
We are proud to announce that CyberGRX has been named as one of the top..
Learn More
3 Questions Healthcare Organizations Should Consider...
Did you know that 33% of third-party data breaches in 2021 targeted healthcare organizations? In..
Learn More
Mapping Assessments Across Standard Frameworks More...
Maintaining a standard security framework has become increasingly crucial for businesses in today's digital age...
Learn More
ProcessUnity is a Leader in the...
The results are in: ProcessUnity is a Leader in The Forrester Wave™: Third-Party Risk Management..
Learn More
Can You Apply Zero-Trust to Your...
The federal government shifted to a zero-trust strategy in 2022 to bolster its cybersecurity posture; private..
Learn More
CyberGRX Redefines Third Party Cyber Risk...
Company experiences three-digit customer and revenue growth in Q1 alone; brings first-of-its-kind features to market..
Learn More
Webinar: Cyber Risk Intelligence and the...
Register & attend this session as we explore: Third-party cyber risk management vs self-assessments Cyber..
Learn More
The ONE Thing All Modern Third-Party...
At CyberGRX, we’re fortunate to engage with the brightest minds in the third-party cyber risk..
Learn More
Managing the Security Risks in Third-Party...
While the average cost of a data breach, $3.86 million, is alarming, another statistic also..
Learn More
Why Third-Party Risk Management Saves Businesses...
Small to midsize companies are increasingly feeling financial pressure on their operations. According to Harvard..
Learn More
How Remote Work Has Changed On-Site...
The pandemic caused a shift in how we think about the modern workplace. Pew Research found that..
Learn More
Are Your Suppliers Putting You at...
Global events, such as the Ukraine-Russia conflict, are driving increased risk levels in nearly every..
Learn More
Recorded Future Third-Party Threat Intelligence Insights
Having a single pane view of proven and contextualized datasets helps alleviate resource constraints, allowing..
Learn More
CyberGRX Product Guide
CyberGRX brings a revolutionary approach to third-party cyber risk management. Using sophisticated data analytics, real-world..
Learn More
3 Third-Party Risk Lessons from the...
Proactively mitigate third-party risks with vendor engagement and issue response strategies Lapsus$, a criminal hacking..
Learn More
The 6 Most Common Third-Party Security...
Businesses today are increasingly reliant on third-party vendors to help them run their operations. These..
Learn More
Protecting Your Network From the Increased...
By the start of 2022, about 30% of all employees in the U.S. were working..
Learn More
Why You Need Total Transparency with...
Cybercriminals know only too well how lucrative targeting third parties can be. They have honed..
Learn More
Social Engineering: How to Not Be...
Remember the time you received a phone call from a disgruntled customer or employee that..
Learn More
Leveraging Predictive Risk Profiles for Greater...
With cyber-attacks escalating daily and a constant flow of headlines about ransomware demands bringing supply..
Learn More

Understanding Your Cybersecurity Risks During the...
Cybersecurity experts warn that conflict in Ukraine presents ‘perhaps the most acute cyber risk U.S...
Learn More

War in Ukraine: Monitoring Resiliency in...
As the world turns its attention towards the escalating conflict between Russia and Ukraine, companies..
Learn More
5 Areas to Mitigate Risk in...
If you work within a Vendor Risk Management (VRM) team, you know that third-party risk..
Learn More
Beyond Risk Management: How Cyber Risk...
Definitions of the word intelligence include a collection of information of military or political value..
Learn More
Are You Ready for the PRA's...
The clock's ticking. If you're a financial services institution regulated by the Prudential Regulatory Authority,..
Learn More

Why Retailers Need Cyber Risk Intelligence...
The retail industry is one of the biggest contributors to the Gross Domestic Product (GDP)..
Learn More

How to Improve Your Vendor Due...
You can't do business without your vendors. They support critical elements of your organization, from..
Learn More
Building Your Intelligent Risk Portfolio
Companies increasingly rely on third parties to do business. With this, comes an increased vulnerability..
Learn More
3 Reasons to Align Cybersecurity and...
In the face of increasingly common and costly data breaches, your organization needs to know how..
Learn More
Log4j: How Organizations Address Cybersecurity with...
The discovery of the Log4j vulnerability is the latest incident to send organizations into panic about..
Learn More

Log4j Vulnerability: A Lesson in Third...
A vulnerability was recently detected in Log4j, an open-source logging framework web developers use to..
Learn More
Log4Shell and Threat Profiles
The Log4Shell attack has shown, once again, how important it is to know the cybersecurity postures..
Learn More
Log4Shell and Third-Party Vendors: How Will...
With the whole world losing their marbles over the Apache Log4Shell vulnerability (and rightfully so),..
Learn More
The Difference Between Third-Party Cyber Risk...
Major security incidents have shed light on the cyber risks associated with third-party suppliers and..
Learn More
How To Create a Results-Driven Supplier...
Seventy percent of organizations have under-invested in their supplier risk assessments. This fact is startling given the growing reliance organizations have on..
Learn More
2021 and Beyond: Financial Viability Trends...
Experts from ProcessUnity and RapidRatings recently got together to discuss why world-class third-party risk management programs are leveraging financial health ratings for onboarding, due..
Learn More
5 Easy Ways to Increase Your...
We want all members of our exchange to leverage their completed CyberGRX assessment as their..
Learn More
How Predictive Analytics Will Keep You...
The GDPR Threat With the Information Commissioner's Office's (ICO) ever increasingly active enforcement of the..
Learn More
4 Reasons to Manage Cybersecurity Controls...
The modern cybersecurity program faces more challenges today than ever before. New worldwide directives and increased cyberattacks put pressure..
Learn More

Predictive Risk Profiles Data Sheet
Predictive Risk Profiles from CyberGRX revolutionize the approach to third-party cyber risk management. By applying..
Learn More
5 Tips to Improve Your Vendor...
Vendor due diligence is essential to any third-party risk management program. However, no two due diligence processes are..
Learn More
How Dynamic Scoping Can Improve Your...
Vendor risk assessments help third-party risk management (TPRM) teams understand the risk their third parties,..
Learn More
Third-Party Vendor Risk Management Challenges for...
Today’s financial institutions face an incredible challenge when it comes to managing their third-party vendor..
Learn More
Build a Better Vendor Due Diligence...
Take a deep dive into vendor due diligence with ProcessUnity’s in-house due diligence specialist, James Goncalves. This interview..
Learn More
3 Steps to Better Vendor Risk...
Creating and distributing vendor risk assessments is a key part of any third-party risk management program. As organizations utilize third-party services to..
Learn More
Expert Interview: Continuous Monitoring of Third-Party...
ProcessUnity discusses best practices for continuous monitoring of third-party vendor risk with BitSight, a leading..
Learn More
Managing Third-Party Cyber Risk
Each day organizations face new threats that jeopardize their critical networks. Standard cybersecurity practices help mitigate the..
Learn More
Why Organizations Automate Vendor Risk Assessments
It’s a fact increasingly validated with each third-party data breach: when an organization brings on..
Learn More
ISACA Summit Replay: Cybersecurity is an...
Throughout your company, people are managing silos of cyber risk to your business. You need..
Learn More
CyberGRX vs. Competitors: A Comparison Chart
Selecting an effective TPCRM program can be a daunting task. While there may be similarities..
Learn More
Inherent Risk vs. Residual Risk in...
Conducting a thorough vendor risk analysis is an integral step in Vendor Risk Management. However,..
Learn More
ProcessUnity Team Kicks Off National Day...
On August 20th, 2021, ProcessUnity hosted its inaugural Day of Giving to provide our team with the..
Learn More
UK PRA Guidelines: New Strategies for...
It goes without saying that operational resiliency and supplier risk management go hand in hand. Organizations need to adapt, respond to, and..
Learn More
What the Biden Administration's Executive Order...
The Biden Administration is prioritizing the nation’s cybersecurity with an executive order to modernize cybersecurity defenses and protect..
Learn More
Ransomware & Your Third Parties: A...
Ransomware continues to dominate headlines with no sign of slowing down. What started more than..
Learn More
Introducing Enhanced Portfolio Management Features
We know that successful third-party cyber risk management requires a collaborative, comprehensive approach. With three..
Learn More
How to Create a Mature Third-Party...
Whether building a program from scratch or improving an existing program, third-party risk management (TPRM)..
Learn More
What is Third-Party Risk Management?
Third-Party Risk Management is the process of identifying, managing and mitigating risks present in a vendor relationship. This..
Learn More
ESG Reporting Mandates to Know for...
Third-Party Risk Management in today’s regulatory landscape is difficult – and it is about to..
Learn More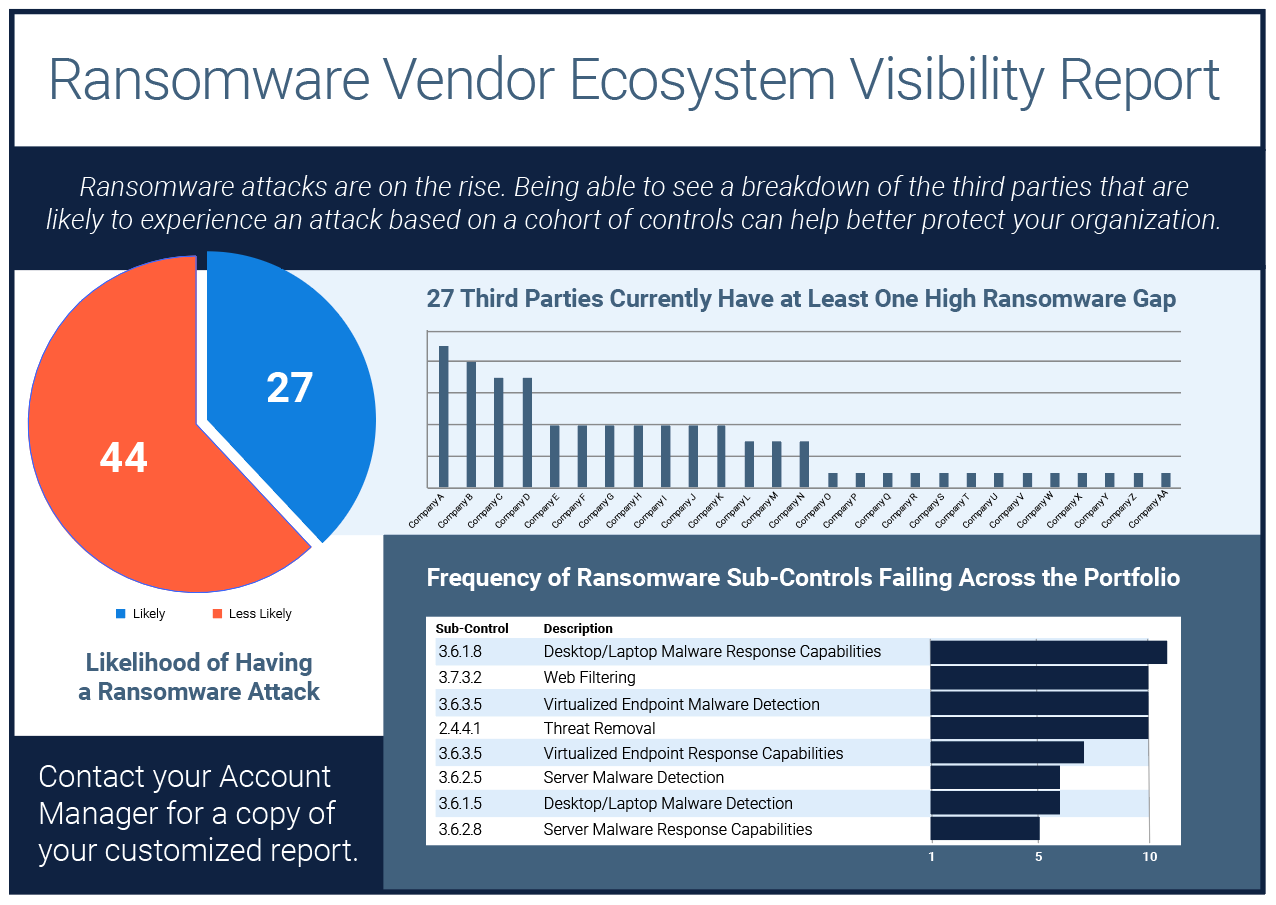
Ransomware Vendor Ecosystem Visibility Report
If knowledge is power, then visibility is the secret weapon against ransomware and extortionware.With our..
Learn More
7 of the Most Notable Ransomware...
As we mentioned in a previous post, ransomware attacks have been happening for many years..
Learn More
Diversity and Inclusion as a Third-Party...
Diversity and inclusion initiatives are helping organizations to increase profitability, boost their reputation and even..
Learn More
The Evolution of Ransomware
Ransomware is a type of malware that when deployed, encrypts files on a victim’s computer..
Learn More
What is Fourth Party Risk and...
As we’ve seen in recent events such as the SolarWinds hack, third-party risk poses a serious threat to business continuity. What the..
Learn More
CyberGRX Ransomware Threat Profile & Ecosystem...
In order to fight ransomware, companies need a methodology that combines a wide range of..
Learn More
Exchanges, GRC Tools, and Risk Scans:...
It’s like comparing apples to baseball stadiums: If you are (or will be) evaluating solutions..
Learn More
Supplier Risk Management Strategies for Healthcare...
The COVID-19 pandemic served as a wake-up call for supplier risk management programs globally. Formerly reliable..
Learn More
REvil’s Reign: Kaseya VSA Ransomware Supply...
Recently, thousands of Kaseya VSA servers were exploited using a malicious update payload. Bypassing access..
Learn More
The Next Kaseya Breach is Around...
While the July 4th weekend meant celebrating the United States’ Independence Day holiday for some,..
Learn More
Setting Up A Cybersecurity Assessment Schedule
Building an Informed Cybersecurity Assessment Schedule Managing a cybersecurity program demands regular reviews of key..
Learn More
Risk Assessment Methodology Data Sheet
CyberGRX cloud-based assessments are the industry’s only comprehensive assessment methodology to manage risk across security,..
Learn More
Managing a Cybersecurity Budget: Where to...
As humans, we all have fight or flight instincts that kick in during dire situations...
Learn More
How To Create A Barebones Production...
I’ve recently had the opportunity to step into a tech lead role at CyberGRX, and..
Learn More
The Impact of NERC and FERC...
Cyber threats and their subsequent attacks are dominating news headlines globally. The recent SolarWinds attack..
Learn More
Your Cybersecurity Budget is a Top...
Cybersecurity is recognized as an increasingly important annual budget spend, with many organizations declaring their cybersecurity..
Learn More
Anatomy of a Third-Party Data Breach
According to research done by the Ponemon Institute, third-parties are involved in over half of..
Learn More
Why Vendor Risk Management is Essential...
Third-Party Risk in Healthcare When it comes to vendor risk management in healthcare, regulators increasingly..
Learn More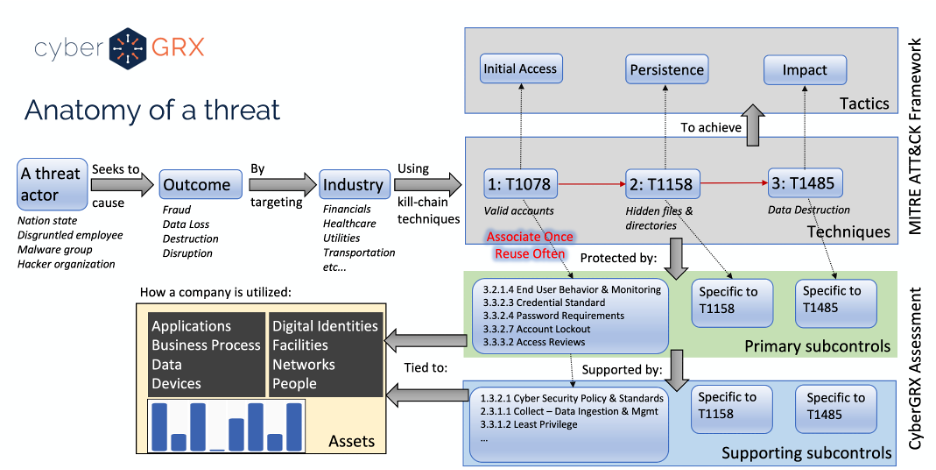
Cybersecurity Analytics: Integration With the MITRE...
Deriving insights from a cybersecurity assessment requires the structure of real-world threat narratives. Companies in..
Learn More
The Benefits of a Centralized Cybersecurity...
Implementing a centralized Cybersecurity Program Management platform can pay dividends for your organization by protecting high-value..
Learn More
Do You Really Know Who Your...
Money laundering; bribery and corruption; drug trafficking; and terrorism financing are issues that are rapidly infiltrating business operations. In recent years,..
Learn More
3 Secrets to Building a Winning...
Did you know third-party breaches account for over half of all data breaches in the..
Learn More
Attack Scenario Analytics: A Datasheet Reference
The MITRE ATT&CK framework has become a global standard for analyzing tactics and techniques used..
Learn More
Expert Tips for Setting up a...
Assessing Third Party Risk with a Vendor Questionnaire Vendors deliver reduced costs and increased productivity, making them very advantageous for business strategy...
Learn More
Vendor Risk Management & ESG Related...
The Emerging Importance of ESG-Related Risk Environmental, social, and governance (ESG) and its role in vendor..
Learn More
CyberGRX Partners with Recorded Future to...
We're excited to announce we've formed a strategic partnership with Recorded Future, the world’s largest..
Learn More
What’s the Difference? Vendor Risk vs...
The words are frequently used interchangeably. Is there a difference between them? The Basics of Third Party..
Learn More
The Intersection of Third-Party Risk and...
According to a recent BlueVoyant, Opinion Matters global study of 1,500 CISOs, CIOs, and CPOs, 29 percent say they have..
Learn More
Solarwinds Hack: The Intersection of Cybersecurity...
The continuing fallout from the SolarWinds hack is creating a mashup of Cybersecurity Program Management stuffed..
Learn More
Anti-Bribery & Corruption (ABAC) in Business...
The impacts of corruption can be very severe and have been historically well documented. On a political level, corruption – however and wherever..
Learn More
The Cyber Info Exchange Episode 7:...
The world of technology and security covers a magnitude of critical topics in all things..
Learn More
Cybersecurity Accountability Requires Enterprise-Wide Involvement
Cybersecurity is every employee’s responsibility. To ensure success, organizations today need to weave cybersecurity accountability into the..
Learn More
8 Key Reports You Need for...
The foundation for an effective vendor risk program starts with solid reporting. As your vendor..
Learn More
Stay Ahead of the Cybersecurity Threat...
Understanding today’s ever-evolving cybersecurity threat landscape is essential for developing strategies and taking action to..
Learn More
Checklist: TPCRM in the Retail Industry
The CyberGRX platform brings visibility, scalability, and accuracy to third-party cyber risk management programs (TPCRM)..
Learn More
Stop Wondering if You're Compliant: The...
Regulations and compliance requirements are constantly changing, and this can make it challenging to efficiently maintain compliance...
Learn More
Tips for Quantifying Inherent Risk for...
Quantifying inherent risk for third parties is one of the most important aspects of a..
Learn More
The Cyber Info Exchange Episode 6:...
The world of technology and security covers a magnitude of critical topics in all things..
Learn More
What Is Third-Party Risk Management: The...
The recent SolarWinds breach has reminded news organizations, businesses, and leadership teams around the world..
Learn More
The Importance of a Flexible Cybersecurity...
It goes without saying: Your cybersecurity threat landscape is continually evolving, and new risks emerge each day. Trends..
Learn More
EBA Guidelines and Supplier Risk Management
Today’s distributed, business environment is defined by third-party relationships. The boundaries of the organization have..
Learn More
How to Stop the Next SolarWinds...
The SolarWinds breach, while incredibly serious, is a flash in the pan brought upon by..
Learn More
Reporting on the State of Your...
The CISO’s Role and Cybersecurity Program Evolution As the role of the CISO changes and..
Learn More
Cybersecurity Risk has Changed the Chief...
In the past, the Chief Information Officer (CIO) was responsible for all things technology, but..
Learn More
How to Address The Top Third-Party...
Third-party risk management, or TPRM, is a critical part of keeping your company’s and customers’..
Learn More
What is a Cybersecurity Framework?
A cybersecurity framework is the foundation on which your program is built. It documents the..
Learn More
8 Benefits of Completing a CyberGRX...
CyberGRX modernizes and streamlines redundant and inefficient processes that come with shared and static..
Learn More
Are Third-Party Cloud Applications Putting Your...
In May of 2017, it was discovered that an exposed data repository, an AWS S3..
Learn More
Third-Party Risk Management Best Practices
New Guide Offers Expert Advice for Effective and Efficient Vendor-Risk Processes A robust, effective, and..
Learn More
Blackstone ROI One-Pager
Contact us today CyberGRX’s platform has helped Blackstone create a more efficient third-party risk management..
Learn More
QBE ROI One-Pager
When they determined the number of third-party cyber risk assessments they’d be doing was going..
Learn More
Blackstone Case Study
With a rapidly growing business that includes a robust vendor ecosystem and portfolio of companies,..
Learn More
TPCRM 101 Guidebook
In the cyber sphere, NIST, ISO, AICPA, and DHS are among the multiple organizations that..
Learn More
Gartner Names ProcessUnity a Leader in...
The title says it all – Gartner has again recognized ProcessUnity as a Leader in..
Learn More
Why Vendor Risk Management Should Be...
As the severity and cost of data breaches continues to increase, Vendor Risk Management has never been..
Learn More
What is Data Privacy and How...
The General Data Protection Regulation (GDPR) brought data privacy issues to the doorstep of organizations..
Learn More
The Evolution of the Third-Party Due...
To compete in today’s marketplace, companies routinely engage third parties to provide all manner of..
Learn More
QBE: Improving Oversight of Third Parties...
As a major insurer operating in 27 countries, QBE has a large vendor footprint and..
Learn More
Procurement or Information Security: Who Owns...
There is no right answer to which team should own Third-Party Risk Management, but effective..
Learn More
Auto Inherent Risk Data Sheet
If you’re still using static assessments, you’re likely missing out on vital risk intelligence. CyberGRX..
Learn More

Compliance Week Recognizes Abercrombie & Fitch’s...
Congratulations to Rob Seibel, Director of Legal Compliance at Abercrombie & Fitch Co., for receiving..
Learn More
7 Security Controls You Need For...
It’s no secret that data protection and security has become a hot topic in recent..
Learn More
Revolutionizing Third Party Risk: How to...
Despite their best efforts to administer an efficient and effective process, many organizations spend an..
Learn More
Pandemic Questionnaire Guidance & Vendor Assessment...
Before the emergence of COVID-19, third-party risk management programs were executing in a business-as-usual mode,..
Learn More
The Cyber Info Exchange Episode 5:...
The world of technology and security covers a magnitude of critical topics in all things..
Learn More
The Cyber Info Exchange Episode 4:...
The world of technology and security covers a magnitude of critical topics in all things..
Learn More
ComplySci ROI One-Pager
By proactively sharing their CyberGRX assessment, ComplySci has cut down the time they spend filling..
Learn More
How Third-Party Risk Management Can Help...
This post originally appeared on LinkedIn. To view the original article, click here. We understand the..
Learn More
How to Spot Your Riskiest Vendors:...
Maintaining strong relationships with third parties is critical to business success. Yet too often, does..
Learn More
Third-Party Risk Management: From A to...
Just as the mind, body and spirit are intertwined, there are several interconnected pillars to..
Learn More
APRA CPS 234: Everything You Need...
The Office of the Australian Information Commissioner reported that there were over 950 data breaches..
Learn More
Metrics to Avoid When Discussing Cybersecurity...
Chief Information Security Officers (CISOs) have one of the toughest jobs in the C-Suite. They..
Learn More
2019 Was A Banner Year for...
ProcessUnity just finished up another banner year – it’s an exciting time to be in..
Learn More
Outside-In Scanning Is Not Cyber Risk...
Risk management is fairly straight-forward as a strategic concept but is complicated by a myriad..
Learn More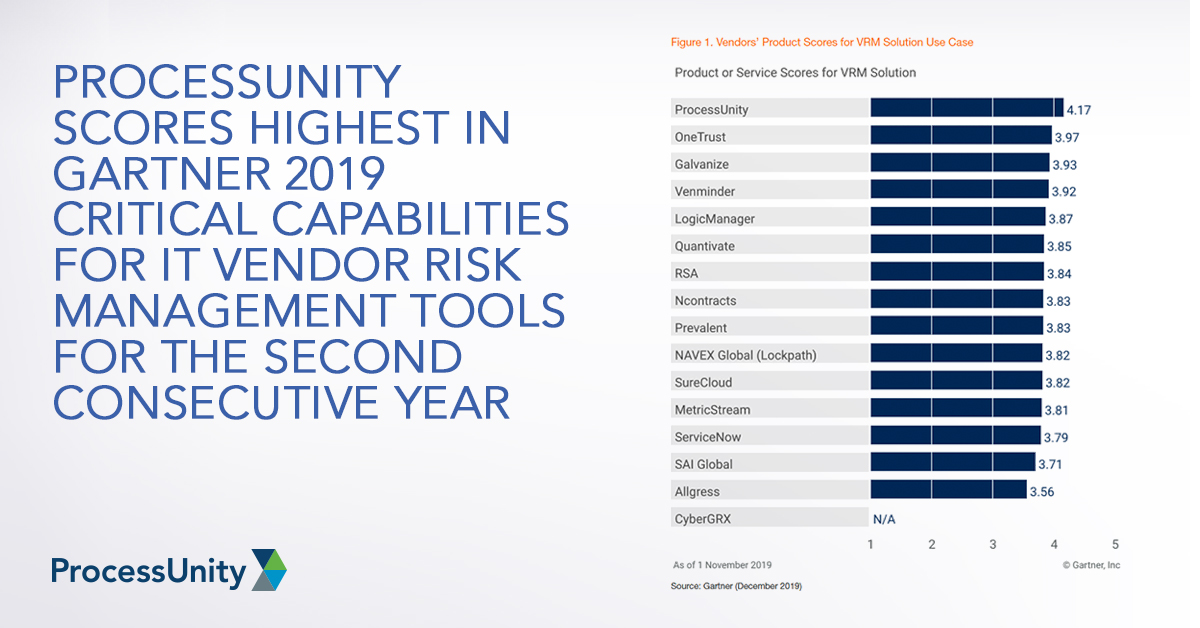
ProcessUnity Scores Highest in Gartner 2019...
Gartner recently published the 2019 Critical Capabilities for IT Vendor Risk Management Tools, and we..
Learn More
CPG Case Study
With an extensive portfolio of third-parties, a leading CPG company needed a streamlined third-party cyber..
Learn More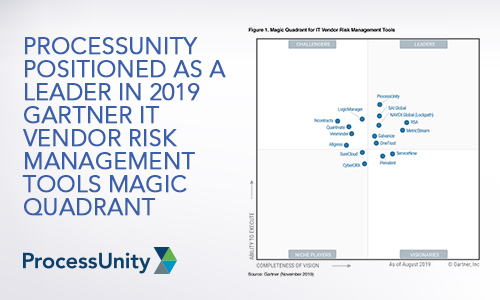
ProcessUnity Positioned as a Leader in...
We have great news. Today, Gartner published the 2019 Magic Quadrant for IT Vendor Risk..
Learn More
What the European Banking Authority Guidelines...
Using the European Banking Authority (EBA) guidelines to streamline your supplier risk management program Simply..
Learn More
Solix Case Study
Solix Shares the CyberGRX Assessment Driving Business and Saving Time One Assessment For All After..
Learn More
The Latest CCPA Update: Amendments to...
As we learned from, “A Finance Exec, A Real Estate Developer, And a Former CIA..
Learn More
Why Your Third-Party Risk Management Program...
The vast majority of people get annual physical examinations and automotive tune-ups – why shouldn’t..
Learn More
How To Improve Your Third-Party Inherent...
More than two-thirds of companies are cutting corners when it comes to third-party due diligence..
Learn More
The Latest Retail Breaches: Third-Party Data...
Third-party data breaches have been dominating the headlines in 2019, with a lot of the..
Learn More
CCPA and GDPR Compliance for IT...
For many of us that work in IT Fields, the requirements of privacy bills like..
Learn More
Sarbanes-Oxley Compliance: Five Steps to Cleaning...
While Sarbanes-Oxley (SOX) compliance management may be old hat for some, organizations today continue to..
Learn More
CyberGRX Enriches Third-Party Cyber Risk Management...
CyberGRX Auto Inherent Risk Automates a Time-Consuming, but Critical Step, Bringing Immediate and Valuable Insights..
Learn More
Hey Third Parties! Here's How to...
If you have a partner that trusts you with their business – and therefore, data..
Learn More
Tips for Preparing For Your Third-Party...
Being the target of a cybersecurity assessment can be frightening. Cybersecurity covers a broad set..
Learn More
How Financial Ratings and Cybersecurity Scores...
RapidRatings, Security Scorecard and BitSight Enhance Vendor Risk Management Process As a standalone solution, ProcessUnity’s..
Learn More
Poll: Over Half of Risk Managers...
ProcessUnity recently participated in a live webinar with IT GRC and other leading Vendor Risk..
Learn More
First GDPR, Now CCPA: Manage Your...
One year ago, organizations of all sizes were scrambling to comply with the pervasive General..
Learn More
Essential Technical Security Controls to Promote...
One of the most impactful regulations in the U.S. is the Health Insurance Portability and..
Learn More
Evaluating Third-Party Risk Management Software? Speed...
Good vendor risk management practices are good for business. Unfortunately, most organizations today continue to..
Learn More
It’s a Wrap: Four Takeaways from...
The 2019 ProcessUnity Customer Summit is a wrap and what a week it was. We..
Learn More
Creating a Third-Party Cyber Risk Management...
I’ve spent almost 30 years in the IT security space and half of that engaged..
Learn More
Cyber Risk: What is it and...
Cyber risk is a hot topic these days, and rightfully so. By 2025, Gartner estimates that “45%..
Learn More


The Cost of Third-Party Cybersecurity Risk...
Third parties are inundated with assessments and enterprises aren't getting the insights they need -..
Learn More
Trust, But Validate: Building Confidence in...
Overview Security assessments come in all shapes and sizes. Some have tightly defined scopes and..
Learn More
How ComplySci Spends Less Time on...
ComplySci Proactively Shares CyberGRX Helps ComplySci Reduce Time Spent on Assessments with Proactive Sharing Proactive..
Learn More
How Blackstone Assessed 3x More Vendors...
Blackstone Assesses 3x More Vendors CyberGRX Is A Force Multiplier for Third-Party Cyber Risk Management..
Learn More
5 Reasons to Share Your CyberGRX...
One of the greatest benefits of having a CyberGRX assessment on the Exchange is the..
Learn More
5 Reasons to Accept a CyberGRX...
A partner wants to share a CyberGRX assessment with you, why should you accept? Step..
Learn More
Third-Party Management Maturity Model White Paper:...
ProcessUnity’s recent white paper, the “Third-Party Risk Management Maturity Model,” helps you understand where your..
Learn More
New Gartner Report: Evaluates Capabilities and...
Gartner Research recently published The 2018 Critical Capabilities for IT Vendor Risk Management, and we are extremely excited..
Learn More
Technology Case Study
After a technology company doubled the size of their vendor ecosystem, they sought to secure..
Learn More
Third-Party Risk: Reduce Vendor Fatigue &...
You’ve likely heard before that “one size does not fit all” when it comes to..
Learn More
ComplySci Case Study
ComplySci Proactively Shares CyberGRX Helps ComplySci Reduce Time Spent on Assessments with Proactive Sharing Proactive..
Learn More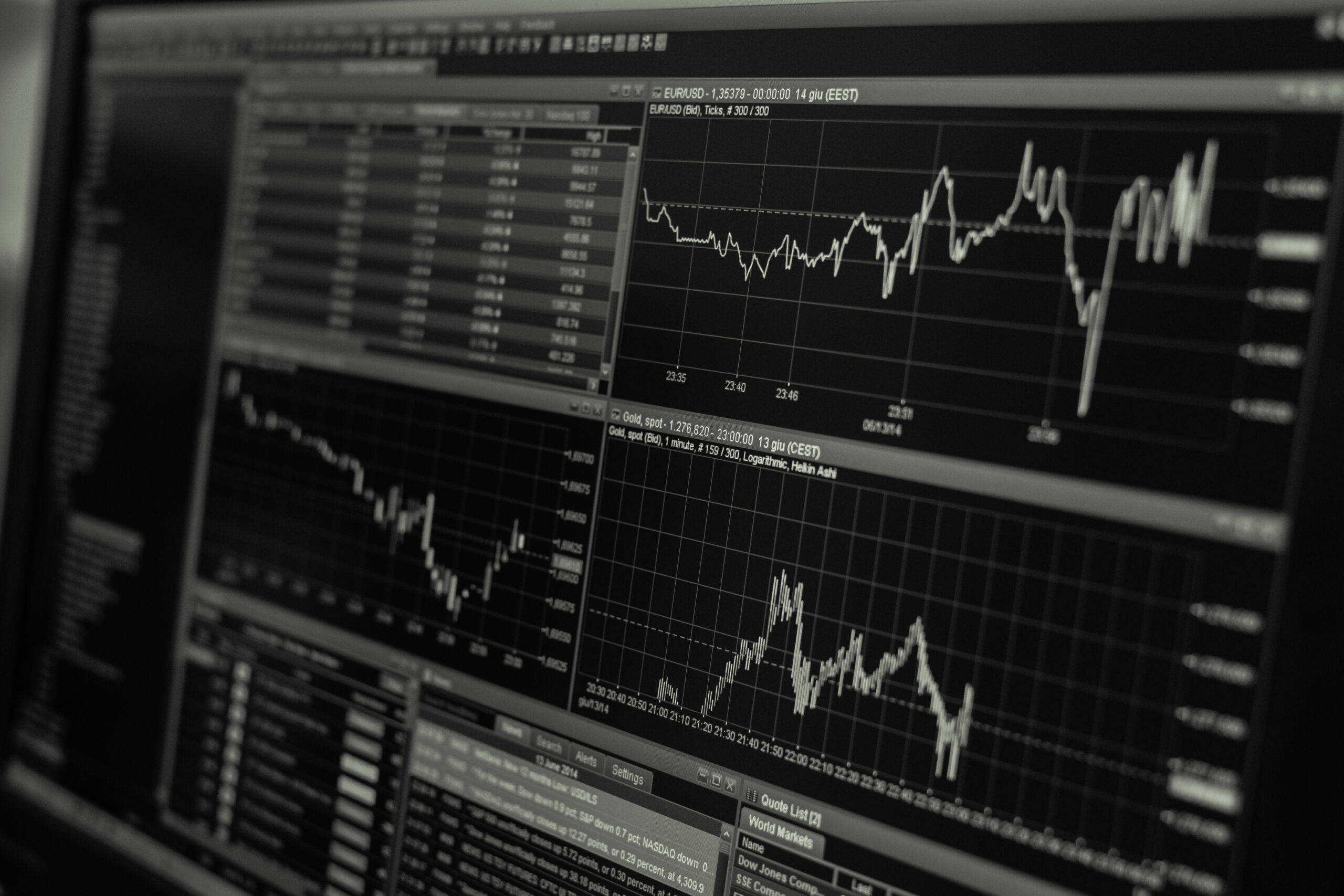
New Report Predicts Significant Market Growth
MarketsandMarkets has published a new report that states that the global Vendor Risk Management market..
Learn More
Vendor Onboarding Best Practices: ProcessUnity Webinar...
Vendor Onboarding Best Practices: To contract a vendor is to initiate a relationship: when you..
Learn More
Think GDPR (General Data Protection Regulation)...
Do you collect, store or process EU citizen or resident data? Does anyone in your..
Learn More
Risk & Compliance – The Build...
We’re not seeing it as much as we used to, but some companies are still..
Learn More
Incorporating Content Services into Your Vendor...
Companies are continually searching for ways to improve the quality of their third-party risk due..
Learn More
Regulatory and Management Reporting for Vendor...
In working with prospects and customers, one of the questions I get asked the most..
Learn More
SLAs and Vendor Performance Management
Not all business relationships require a service-level agreement (SLA), but good vendor performance management is..
Learn More
Formalizing Vendor Risk Management - Keep...
When starting to build a formal Vendor Risk Management program, it’s important not to overcomplicate..
Learn More
Six Tips for Building Effective Vendor...
A well-designed vendor risk assessment questionnaire is vital for a successful Vendor Risk Management program...
Learn More
The 2017 State of Third Party...
How does your program rate? Take the Third-Party Risk Management survey and find out! There..
Learn More
eBook: 8 Reports for Effective and...
The foundation for an effective and efficient Vendor Risk Management program is solid reporting. The..
Learn More
The Top Policy and Procedure Management...
Corporate policies – from HR guidelines to pricing rules -- set the standards, outline the..
Learn More
How to Stay Ahead of Risk...
Managing risk through pre-contract vendor due diligence in a digitally connected world Thanks to increasing..
Learn More
Mitigating the CFPB Audit Process
In the mortgage industry, the potential for an audit by the Consumer Financial Protection Bureau..
Learn More
Why Cloud Works for Third-Party Risk...
If you are running a Vendor Risk Management program, odds are that you either have:..
Learn More
The Hidden Costs of Spreadsheets in...
While spreadsheets are a widely-accepted go-to for compliance and risk management activities, findings from Blue..
Learn More
The State of Third-Party Risk Management
Today, organizations are bombarded by new regulatory guidance, daily occurrences of cybercrime and data breaches,..
Learn More
45-Minute Executive Web Clinic: Offer Management...
You’ve probably heard: The sky is falling in the benefits industry. (Or should we say..
Learn More
FFIEC Cybersecurity Assessment Tool: What You...
Cybercrime is a hot topic among GRC practitioners these days. It should be. According to..
Learn More
Case Study: Offer Management Revitalizes a...
A large Benefits Provider was facing major customer service and implementation challenges. The company provides..
Learn More
Change Your SOX: Next-Gen Sarbanes-Oxley Compliance
It’s been more than a decade since Sarbanes-Oxley became the law of the land—and..
Learn More
Introducing ProcessUnity’s Summer 2015 Release
Salesforce and Microsoft Office Integrations, plus a Whole New Look! The ProcessUnity Summer 2015 product..
Learn More
Channel Your Inner Regulator to Improve...
If you are like most banks and financial service companies, then chances are you outsource..
Learn More
Five Keys to Conducting Effective Vendor...
Risk exposure is indiscriminate. Whether you are a large multinational, a non-profit institution, an agency..
Learn More
A Roadmap for Implementing Product and...
“Benefit plan providers are turning to Offer Management initiatives and systems to reduce risk, cost..
Learn More
Plan Providers: Use Offer Management to...
In today’s intensely competitive benefit plan market, getting your teams aligned creates a dramatic competitive..
Learn More
Does Your Pre-Contract Due Diligence Leave...
Today’s global, digital economy opens up a world of opportunities—and a whole new world of..
Learn More
Welcome to the ProcessUnity Blog
On behalf of the ProcessUnity team, I am excited to welcome you to the new..
Learn MoreAbout Us
ProcessUnity is a leading provider of cloud-based applications for risk and compliance management. The company’s software as a service (SaaS) platform gives organizations the control to assess, measure, and mitigate risk and to ensure the optimal performance of key business processes. ProcessUnity’s flagship solution, ProcessUnity Vendor Risk Management, protects companies and their brands by reducing risks from third-party vendors and suppliers. ProcessUnity helps customers effectively and efficiently assess and monitor both new and existing vendors – from initial due diligence and onboarding through termination. Headquartered outside of Boston, Massachusetts, ProcessUnity is used by the world’s leading financial service firms and commercial enterprises. For more information, visit www.processunity.com.