ProcessUnity is a Leader in the 2024 Forrester Wave™
ProcessUnity is a Leader in The Forrester Wave™: Third-Party Risk Management Platforms, Q1 2024 with the top scores in the Current Offering and Strategy categories. Download a complimentary copy of the Wave to learn why.



CyberGRX is Now the Global Risk Exchange. Access More than 15,000+ Completed Assessments.
A Single Platform to Manage
Third-Party Risk and Cybersecurity Risk
The ProcessUnity platform reduces third-party risks and cybersecurity threats - two of the biggest challenges organizations face today.
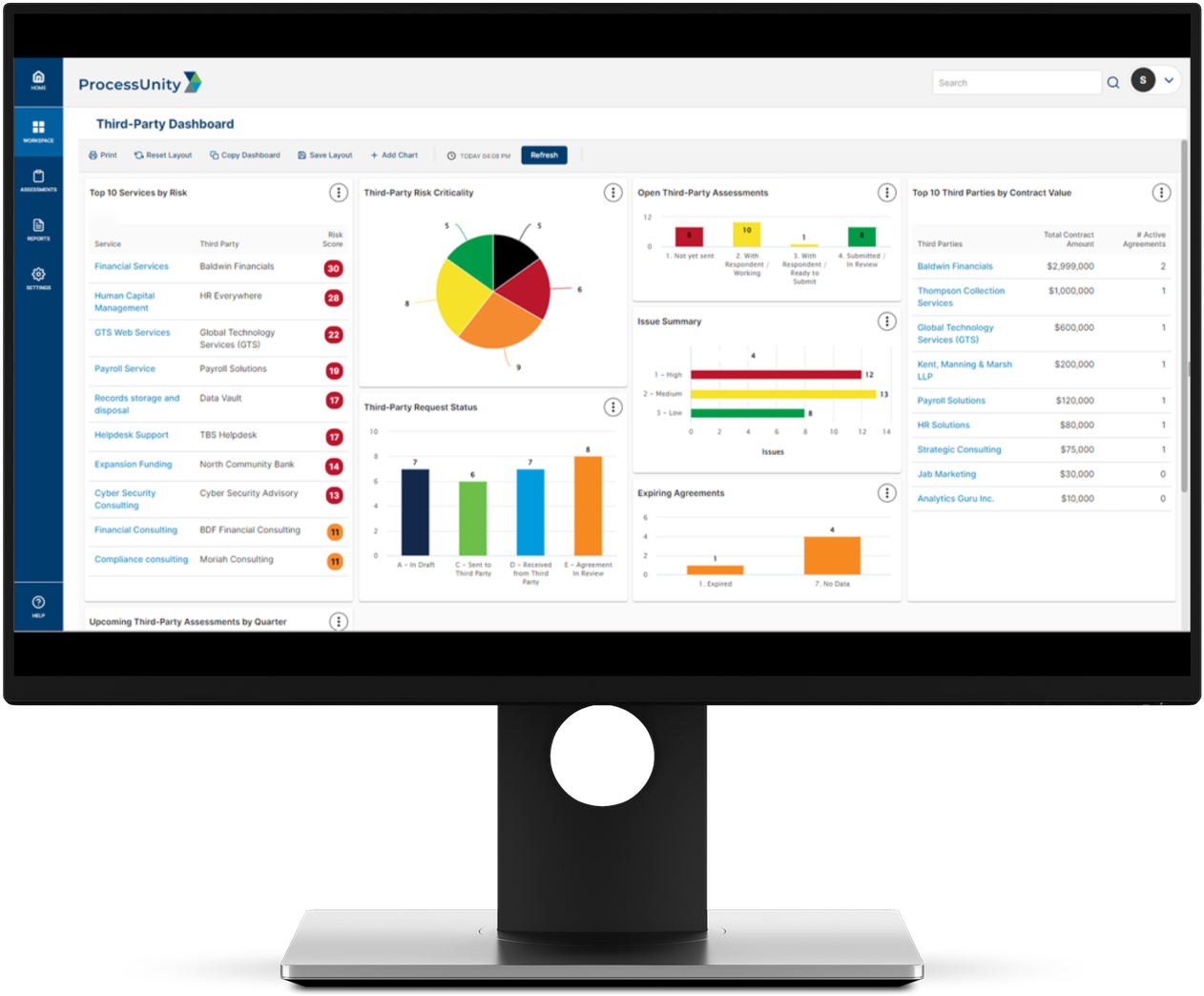
Third-Party Risk Management
The ProcessUnity TPRM Platform protects corporate brands by reducing risk from third parties, vendors and suppliers. ProcessUnity Third-Party Risk Management Platform
Global Risk Exchange
The Global Risk Exchange (formerly CyberGRX) houses the world’s most extensive collection of third-party risk assessments. ProcessUnity Global Risk Exchange
Powerful capabilities for real risk reduction.
A proven track record of customer success.

In interviewing ProcessUnity VRM clients, GRC 20/20 found that they spend approximately 50 percent less time on third-party risk oversight and management activities.”
— Michael Rasmussen, GRC 20/20
Download the Research
GRC 20/20 customer research verifies that ProcessUnity VRM delivers value across the Third-Party Risk Management lifecycle.
The establishment of a third party ‘front door’ and the implementation of ProcessUnity VRM has really energized our procurement team. Thanks to ProcessUnity, we’ve eliminated silos and aligned people, processes, and technology around a standardized third-party risk management program. The investment has really paid off and now we’re working to drive progress forward.”
— Abercrombie & Fitch
With ProcessUnity VRM, GRC 20/20 finds organizations spend less time on ongoing assessments as all information, assessments, tasks, and workflows are conveniently located in one application and readily accessible and easy to report on. This results in a minimum time efficiency savings of 85%.”
— Michael Rasmussen, GRC 20/20
Download the Research
GRC 20/20 customer research verifies that ProcessUnity VRM delivers value across the Third-Party Risk Management lifecycle.
ProcessUnity was the only option that met 99% of our requirements. The other software systems we looked at didn’t allow administrators to change settings on their own. You had to go to the provider for an additional work order, as opposed to ProcessUnity, where all you need to do is make a few clicks. We have the ability to configure the system and make it what we want.”
— Franchesca Williams, Vice President of Third-Party Risk Management, VyStar Credit Union
ProcessUnity has helped us improve our overall TPRM program from a strictly manual process to an organized and automated process... ProcessUnity continually looks for ways to improve their product and listens to their customers in order to gain insight on how to expand their offerings and better service their customers.”
— Gartner Peer Review for ProcessUnity Vendor Risk Management
ProcessUnity Named a 2022 Gartner Peer Insights™ Customers’ Choice for IT Vendor Risk Management Tools
Click the link below to read the full review and other ProcessUnity VRM reviews from your industry peers.

Request a ProcessUnity Demo
Schedule your personalized demo of our award-winning software and start your journey to a more mature, automated program.
Request a ProcessUnity Demo